
关于OpenAI最强模型o3的造假争议,引发了关于其数学推理能力评估和基准测试可靠性的深入探讨。争议焦点集中在模型性能的真实性,以及评估其能力时是否存在偏差。目前,业界正在对这一问题进行深入研究和评估,以澄清事实真相。OpenAI的o3模型面临造假争议,引发关于其数学推理能力评估真实性和基准测试可靠性的讨论,行业正在积极探讨和澄清相关问题。
本文目录导读:
关于OpenAI的最强模型o3(我们假设这是该公司推出的最新且最先进的模型)的争议不断,有报道称该模型在某些情况下出现了“造假”现象,引发了关于其数学推理能力是否真实以及基准测试是否可靠的广泛讨论,本文将深入探讨这些问题,试图从多个角度为读者提供一个全面的视角。
OpenAI o3模型的数学推理能力
OpenAI o3模型作为目前该公司推出的顶尖模型,其数学推理能力在业界内备受瞩目,该模型被期待能够处理复杂的数学问题,从简单的算术运算到复杂的微积分问题,都能轻松应对,近期关于该模型在某些特定情况下“造假”的质疑,引发了公众对其数学推理能力的质疑。
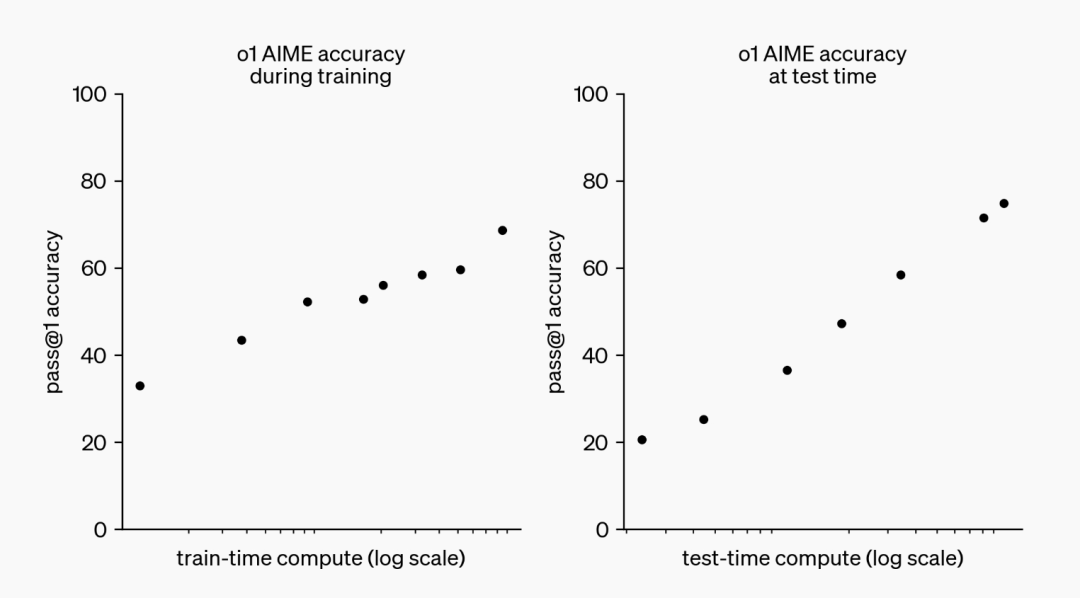
所谓的“造假”,主要是指在某些涉及数学推理的任务中,模型给出了错误的答案或者不完全准确的答案,这种情况的出现,可能是因为模型在处理复杂的数学逻辑时存在缺陷,也可能是因为模型在某些特定情况下出现了偏差,但无论如何,“造假”现象的存在无疑对o3模型的数学推理能力提出了质疑。
o3模型数学推理能力是否被高估
在讨论o3模型的数学推理能力是否被高估时,我们需要从多个角度进行分析,从技术的角度来看,o3模型作为目前最先进的自然语言处理模型之一,其在处理自然语言任务方面的表现无疑是出色的,在处理涉及数学推理的任务时,模型可能会遇到一些挑战,因为自然语言处理和数学推理之间存在本质的差异,自然语言处理更多的是处理语言的含义和语境,而数学推理则需要处理复杂的逻辑和算法,对于o3模型来说,尽管其在自然语言处理方面表现出色,但在数学推理方面仍可能存在局限性。
从实际应用的角度来看,o3模型的数学推理能力是否被高估也取决于其应用场景和目标任务,在某些需要高度精确的数学计算的任务中,如金融、物理等领域,模型的任何偏差都可能导致严重的后果,在这些领域应用o3模型时,需要格外谨慎,而在一些相对宽松的应用场景中,如教育、科普等领域,o3模型的数学推理能力可能足以满足需求。
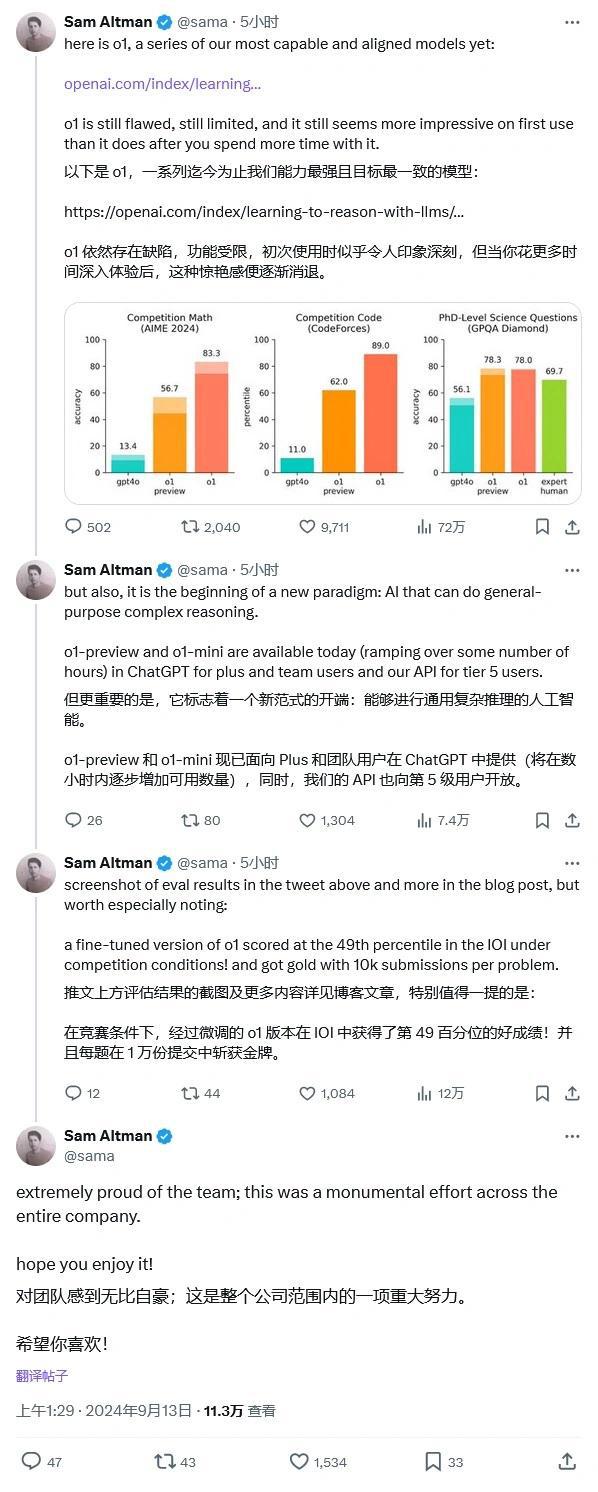
基准测试的可靠性问题
关于o3模型的数学推理能力争议,也引发了人们对基准测试可靠性的质疑,基准测试是衡量模型性能的重要手段,其结果直接影响到人们对模型性能的评估,基准测试的可靠性至关重要。
在实际操作中,基准测试可能会受到多种因素的影响,如测试数据的选取、测试方法的合理性等,如果这些因素处理不当,就可能导致测试结果出现偏差,在评估o3模型的数学推理能力时,我们需要关注基准测试的可靠性问题,为了确保测试的公正性和准确性,我们需要采用多种测试方法,并结合实际应用场景进行评估。
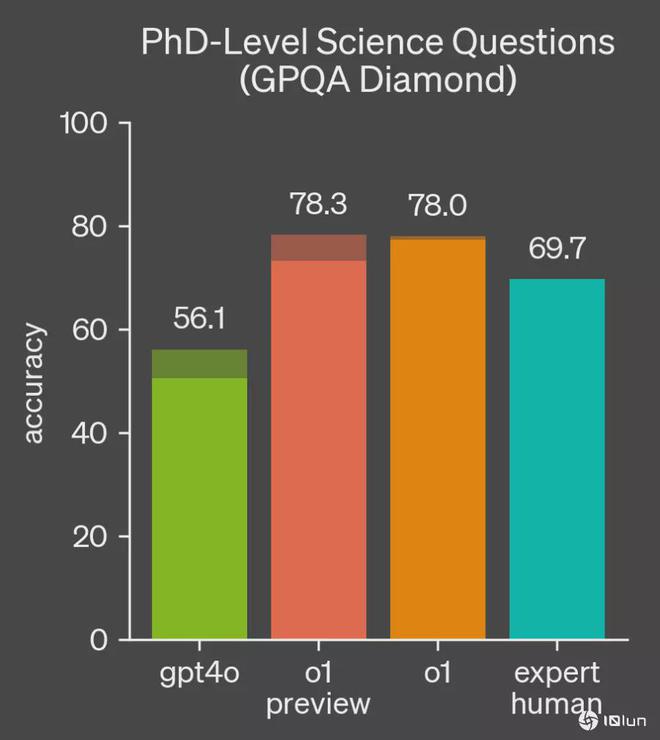
关于OpenAI o3模型“造假”的争议提醒我们,在评估模型的性能时,需要保持谨慎和客观的态度,我们需要从多个角度对模型进行评估,并结合实际应用场景进行分析,我们也需要关注基准测试的可靠性问题,确保测试的公正性和准确性,只有这样,我们才能更准确地评估模型的性能,为未来的研究和应用提供更有价值的参考。
 沪ICP备2021018740号-1
沪ICP备2021018740号-1